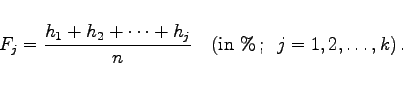Inhalt Index DeskTop Bronstein
![]()
![]() Wahrscheinlichkeitsrechnung und Mathematische Statistik Mathematische Statistik Beschreibende Statistik
Wahrscheinlichkeitsrechnung und Mathematische Statistik Mathematische Statistik Beschreibende Statistik
![]()
![]()
Um eine Eigenschaft eines Elements statistisch zu untersuchen, ist diese durch eine Zufallsgröße X zu charakterisieren. In der Regel bilden dann n Meß- oder Beobachtungswerte xi des Merkmals X den Ausgangspunkt für eine statistische Untersuchung, die vor allem darin besteht, Angaben über die Verteilung von X zu machen.
Jede Meßreihe vom Umfang n kann in diesem Zusammenhang als eine zufällige Stichprobe aus einer unendlichen Grundgesamtheit aufgefaßt werden, die entsteht, wenn der Versuch oder die Messung unter gleichen Bedingungen unendlich oft wiederholt würde.
Da der Umfang n einer Meßreihe sehr groß sein kann, geht man zur statistischen Erfassung der Daten wie folgt vor:
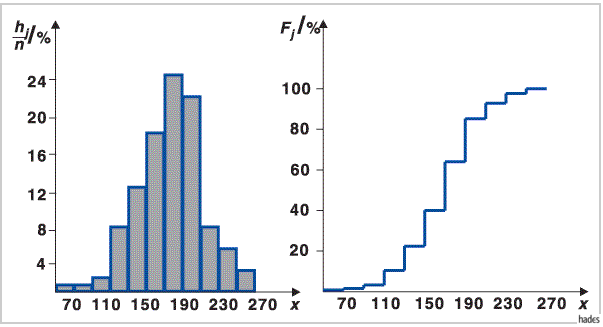
Die Werte hj/n können als empirische Werte der Wahrscheinlichkeitsdichte f(x) interpretiert werden.
Werden die Werte Fj in den oberen Klassengrenzen aufgetragen und als Parallele nach rechts fortgesetzt, dann ergibt sich eine graphische Darstellung für die empirische Verteilungsfunktion, die als Näherung für die unbekannte Verteilungsfunktion F(x) aufgefaßt werden kann (s. rechte Abbildung).